
根據多家外媒周四 (30 日) 報導,Meta Platforms(META-US)、微軟 (MSFT-US)、超微(AMD-US)、博通(AVGO-US) 在內等主要科技公司建立了一個新的產業小組「Ultra Accelerator Link」(UALink),替人工智慧 (AI) 資料中心網路開發新的產業標準。不過該小組獨缺 AI 晶片龍頭輝達(NVDA-US),外媒指出這是為打破輝達領導地位而做出的最新努力。
UALink 推廣小組 (UALink Promoter Group) 周四宣布成立,成員除上述外還包括 Alphabet 旗下 Google(GOOGL-US)、思科 (CSCO-US)、惠普(HPQ-US)、英特爾(INTC-US)。該小組提出一個新的產業標準,用於連接伺服器中越來越多的 AI 加速器晶片。廣義上來說,AI 加速器是從圖形處理器(GPU) 到為加速 AI 模型的訓練、微調和運行而客製化設計的解決方案的晶片。
超微資料中心解決方案總經理 Forrest Norrod 在本周三 (30 日) 的簡報中向記者表示:「產業需要一個可以快速推進的開放標準,在開放的格式中,允許多家公司為整個生態系統增加價值,同時也要一個標準,允許創新以不受任何單一公司束縛的快速步伐進行。」
據了解,UALink 提議的標準的第一個版本「UALink 1.0」將在單一運算「pod」(該小組將 pod 定義為伺服器中的一個或幾個機架) 中連接多達 1,024 個 AI 加速器——僅限 GPU。UALink 1.0 基於「開放標準」,包括超微的無限架構,將允許 AI 加速器附加的內存之間進行直接載入和儲存,並且與現有的互連規格相比,總體上將提高速度並降低資料傳輸延遲。
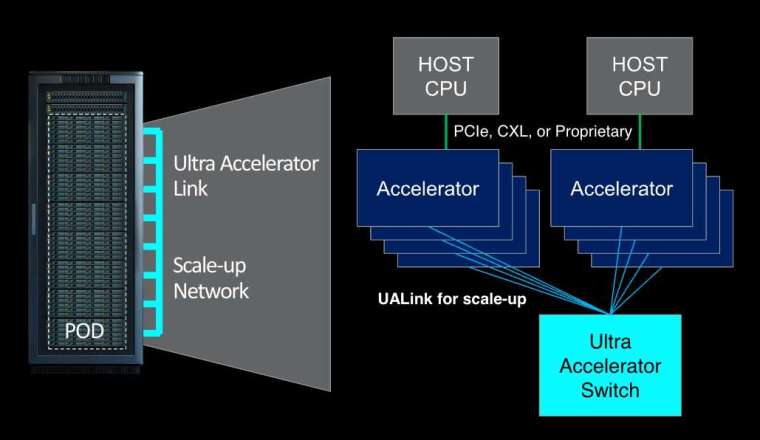
該小組表示,將在第三季創建一個「UALink 聯盟」(UALink Consortium),以監督 UALink 規範的未來發展。 UALink 1.0 將在同期向加入聯盟的公司提供,更高頻寬的更新規範 UALink 1.1,計劃在 2024 年第四季推出。Norrod 表示,UALink 的首批產品將在「未來幾年」推出。
值得注意的是,明顯缺席該小組成員名單的是輝達,該公司是迄今為止最大的 AI 加速器生產商,預估坐擁 80% 到 95% 的市占。輝達拒絕對此發表評論,但不難看出為什麼這家晶片製造商不熱衷於支援基於競爭對手技術的規格。
首先,輝達為其資料中心伺服器內的 GPU 提供了自己的專有互連技術,該公司可能不太願意支援基於競爭對手技術的標準。然後是其從龐大的實力和影響力位置運作的事實,因此簡單來說,如果輝達不想參與就不必參與。
事實上,UALink 的最大受益者——除超微和英特爾——似乎是微軟、Meta 和 Google,它們已經花費了數十億美元購買輝達 GPU 來驅動它們的雲端並訓練其不斷成長的 AI 模型。所有人都希望擺脫一個他們視為在 AI 硬體生態系統中過於主導的供應商。

